Saturday, March 06, 2010
MySQL Life Saver
If you lost your admin password, just follow this. This proved be to a real life saver. Thank god for debian-admin!
Wednesday, March 03, 2010
Monday, March 01, 2010
Gmail account creation != Usability?
Today I have sent an invite to a friend of mine from my gmail account, he got into the registration screen and to his surprise (not much to mine, I know captcha's are getting worse and worse as Internet abuse gets bigger) he couldn't read the letters of the captcha. Being hearing impaired he could also not listen to the captcha being said.
Now, most of the sites I have visited lately have a button to request a new captcha, which might be easier to read, How do you do that in Gmail sign up?
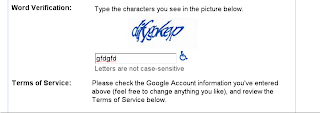
What gives?
Now, most of the sites I have visited lately have a button to request a new captcha, which might be easier to read, How do you do that in Gmail sign up?

What gives?
Wednesday, February 24, 2010
First Nokia Forum Champion In Israel
So, on to some good news - I have recived the Nokia Forum Champion Award today and wanted to share the joy. This is due to my ongoing contribution, promotion QA and testing work that I have been doing since November.
I'd like to so far sincerly thank Janaina, Jure and Sami for their ongoing support and care. Working with Nokia, I feel I am doing cool stuff with techie collegues rather then working with the world's largest manufacturer of mobile telephones.
I hope to visit them sometime soon in Espoo.
I look forward to continue work with Nokia and help them maintain and extend their market share of Mobile devices and applications.
Exciting times are ahead of us, with MeeGo .
"Let the good times roll!" (-Kawaski Jet Ski slogan)
I'd like to so far sincerly thank Janaina, Jure and Sami for their ongoing support and care. Working with Nokia, I feel I am doing cool stuff with techie collegues rather then working with the world's largest manufacturer of mobile telephones.
I hope to visit them sometime soon in Espoo.
I look forward to continue work with Nokia and help them maintain and extend their market share of Mobile devices and applications.
Exciting times are ahead of us, with MeeGo .
"Let the good times roll!" (-Kawaski Jet Ski slogan)
Wednesday, January 13, 2010
Anything you can do we can do better, iPhone.
Tuesday, January 12, 2010
HP Support Phone Line In Israel (nation wide support) BUSY?!?!?
How can it be that a 1-700 line of HP representative in Israel is BUSY?!
Is it so expansive to have a couple of telephone representative to take the calls?
Dear HP, please snap out of it. Israel is a big consumer of your products. Can you please NOT suck badly like an Israeli company?
If there is a franchised lab that is providing the services, and it is not functioning up to standards, let me know, I can help you establish one that will.
I do hope that this issue will not consume too much anger and work on my site, but the touchpad, keyboard and mouse buttons you've put on the HP Compaq Mini 310c are of the saddest combination, and I've never had the misery to use such a malfunctioning pointing device.
Now I will have to wait 2 weeks without a laptop for the matter to be checked, so either it will get fixed or be replaced.
My bad for trying to work with it the couple first months and not going straight to the dealer, who said there was a good chance it would have been replaced.
O' Justice, where are thou ?
Is it so expansive to have a couple of telephone representative to take the calls?
Dear HP, please snap out of it. Israel is a big consumer of your products. Can you please NOT suck badly like an Israeli company?
If there is a franchised lab that is providing the services, and it is not functioning up to standards, let me know, I can help you establish one that will.
I do hope that this issue will not consume too much anger and work on my site, but the touchpad, keyboard and mouse buttons you've put on the HP Compaq Mini 310c are of the saddest combination, and I've never had the misery to use such a malfunctioning pointing device.
Now I will have to wait 2 weeks without a laptop for the matter to be checked, so either it will get fixed or be replaced.
My bad for trying to work with it the couple first months and not going straight to the dealer, who said there was a good chance it would have been replaced.
O' Justice, where are thou ?
Sunday, November 29, 2009
repoze.bfg 1.2a1 released
To all of you that are interested, a new major feature release version is available of repoze.bfg, 1.2alpha1 that includes support for imperative configuration, read more about it here.
Subscribe to:
Posts (Atom)